publications
publications by categories in reversed chronological order. generated by jekyll-scholar.
2026
- Preprint
 When Distance Distracts: Representation Distance Bias in BT-Loss for Reward ModelsTong Xie, Andrew Bai, Yuanhao Ban, Yunqi Hong, Haoyu Li, and Cho-jui Hsieh2026
When Distance Distracts: Representation Distance Bias in BT-Loss for Reward ModelsTong Xie, Andrew Bai, Yuanhao Ban, Yunqi Hong, Haoyu Li, and Cho-jui Hsieh2026Reward models are central to Large Language Model (LLM) alignment within the framework of RLHF. The standard objective used in reward modeling is the Bradley-Terry (BT) loss, which learns from pairwise data consisting of a pair of chosen and rejected responses. In this work, we analyze the per-sample gradient of BT-loss and show that its norm scales with two distinct components: (1) the difference in predicted rewards between chosen and rejected responses, which reflects the prediction error, and critically, (2) representation distance between the pair measured in the output space of the final layer. While the first term captures the intended training signal, we show that the second term can significantly impact the update magnitude and misalign learning. Specifically, pairs with small representation distance often receive vanishingly weak updates, even when misranked, while pairs with large distance receive disproportionately strong updates. This leads to gradients from large-distance pairs to overshadow those from small-distance pairs, where fine-grained distinctions are especially important. To overcome this limitation, we propose NormBT, an adaptive pair-wise normalization scheme that balances representation-driven effects and focuses learning signals on prediction error. NormBT is a lightweight, drop-in integration to BT loss with negligible overhead. Across various LLM backbones and datasets, NormBT improves reward model performance consistently, with notable gains of over 5 precent on the Reasoning category of RewardBench, which contains numerous small-distance pairs. This work reveals a key limitation in the widely used BT objective and provides a simple, effective correction.

2024
- TMLR 2024
 Data Attribution for Diffusion Models: Timestep-induced Bias in Influence EstimationTong Xie, Haoyu Li, Andrew Bai, and Cho-Jui HsiehTransactions on Machine Learning Research (TMLR), 2024
Data Attribution for Diffusion Models: Timestep-induced Bias in Influence EstimationTong Xie, Haoyu Li, Andrew Bai, and Cho-Jui HsiehTransactions on Machine Learning Research (TMLR), 2024Data attribution methods trace model behavior back to its training dataset, offering an effective approach to better understand "black-box" neural networks. While prior research established quantifiable links between model output and training data in diverse settings, interpreting diffusion model outputs in relation to training samples remains underexplored. In particular, diffusion models operate over a sequence of timesteps instead of instantaneous input-output relationships in previous contexts, posing a significant challenge to extend existing frameworks to diffusion models directly. Notably, we present Diffusion-TracIn that incorporates this temporal dynamics and observe that samples’ loss gradient norms are highly dependent on timestep. This trend leads to a prominent bias in influence estimation, and is particularly severe for samples trained on large-norm-inducing timesteps, causing them to be generally influential. To mitigate this bias, we introduce Diffusion-ReTrac as a re-normalized adaptation that retrieves training samples targeted to the test sample of interest, enabling a localized measurement of influence and considerably more intuitive visualization. We demonstrate the efficacy of our approach through various evaluation metrics and auxiliary tasks, outperforming in terms of specificity of attribution by over 60%.
- Preprint
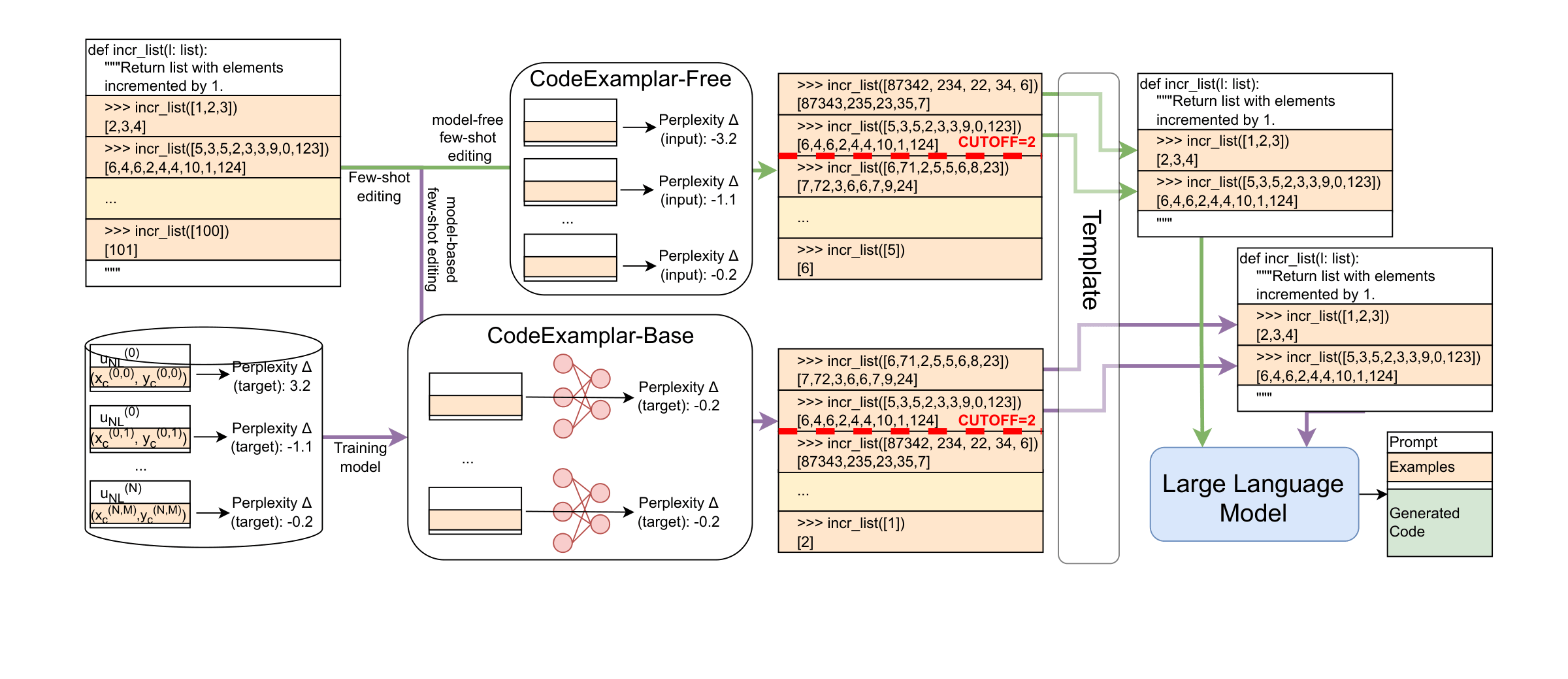 Does Few-Shot Learning Help LLM Performance in Code Synthesis?Derek Xu, Tong Xie, Botao Xia, Haoyu Li, Yunsheng Bai, Yizhou Sun, and Wei Wang2024
Does Few-Shot Learning Help LLM Performance in Code Synthesis?Derek Xu, Tong Xie, Botao Xia, Haoyu Li, Yunsheng Bai, Yizhou Sun, and Wei Wang2024Large language models (LLMs) have made significant strides at code generation through improved model design, training, and chain-of-thought. However, prompt-level optimizations remain an important yet under-explored aspect of LLMs for coding. This work focuses on the few-shot examples present in most code generation prompts, offering a systematic study on whether few-shot examples improve LLM’s coding capabilities, which few-shot examples have the largest impact, and how to select impactful examples. Our work offers 2 approaches for selecting few-shot examples, a model-free method, CODEEXEMPLAR-FREE, and a model-based method, CODEEXEMPLAR-BASED. The 2 methods offer a trade-off between improved performance and reliance on training data and interpretability. Both methods significantly improve CodeLlama’s coding ability across the popular HumanEval+ coding benchmark. In summary, our work provides valuable insights into how to pick few-shot examples in code generation prompts to improve LLM code generation capabilities.

